OSSLab以更詳盡的親自實作,來介紹如何自行對重組RAID碟架構,並進行資料救援。本文章為OSSLab原創文章,翻抄必究!
重組RAID VD (Virtual Drive),可說是最考驗資料救援功力的地方,也是最Tricky的地方。要根據不同陣列卡在硬碟所寫入的磁碟記號(Signature),來一一還原至原先做好的RAID的組態,以下來實際展示此步驟的技術細節:
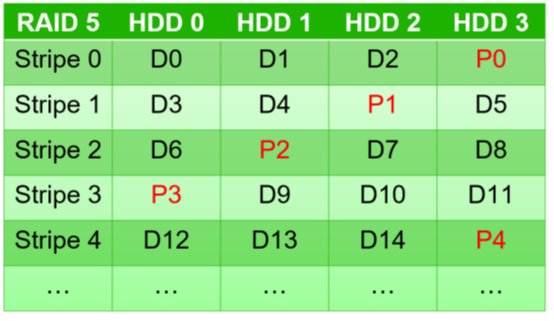
▲大型RAID資料救援工程。第一步驟就是要先重組為原始的硬碟陣列排列方式,尤其當RAID標記不見時,要能分辨出哪些是資料碟(D0~D14),哪些是核對碟(P0~P4)
要如何重組RAID碟的順序,就得先了解各RAID硬碟順序,並分辨出在不同磁區段落中,哪顆存放資料(Data)、哪顆存放核對資料(Parity Data)。本文以3顆HDD做RAID5架構為例,其中1顆的核對資料,就等於其他2顆經過XOR運算後的資料。例如3顆HDD的某Sector (磁區) 第某個Offset (位置) 中,RAID 1碟是55、RAID 2碟是 AA ,那麼RAID 3碟的資料就是55 xor AA = FF (後詳)。
Step-by-Step分析RAID 5碟架構
以下我們實際用3顆HDD在Windows Server下所組成RAID5的基本卷宗來做範例解說。以下的動作主要是先找出3顆HDD的資料碟和核對碟的排列組合。一般NTFS格式化的硬碟資料,可透過下述幾個步驟來找出RAID的排列組合。
-
找出NTFS Boot Loader所在的位置
我們將三顆RAID碟做好鏡像之後,可以透過WinHex同時開啟這三顆硬碟來檢視並同步比對內容。此時先針對3顆HDD進行NTFS Boot Loader的搜尋動作,先找 E3 52 90 4E 54 46 53 20 20 20 20特徵碼,並指定Offset位置為0來開始尋找。如下圖:
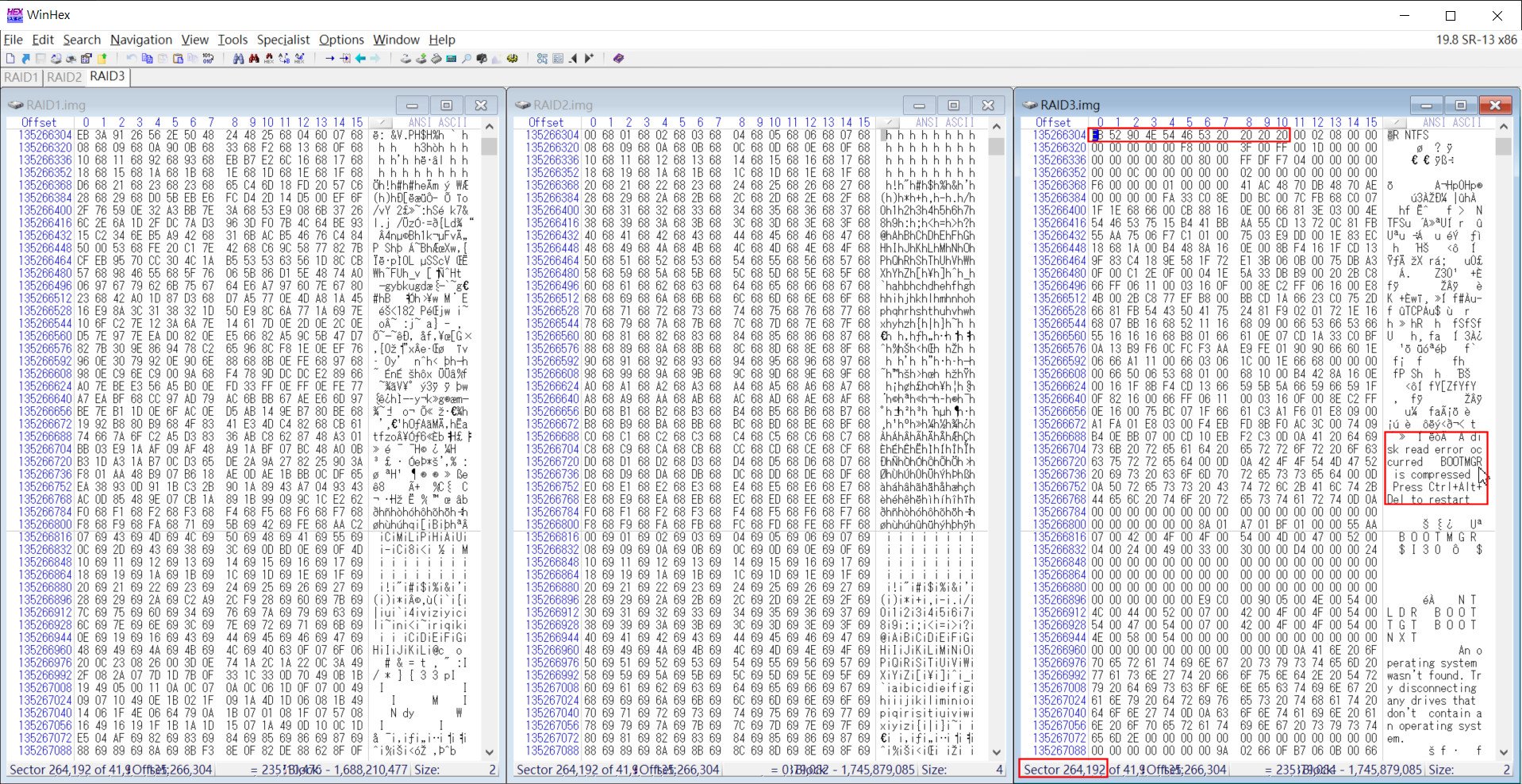
▲以WinHex載入3顆HDD映像檔,並搜尋 NTFS Boot Loader的特徵碼(圖中紅框處),發現可以在RAID3.img的Sector 264,192優先找到
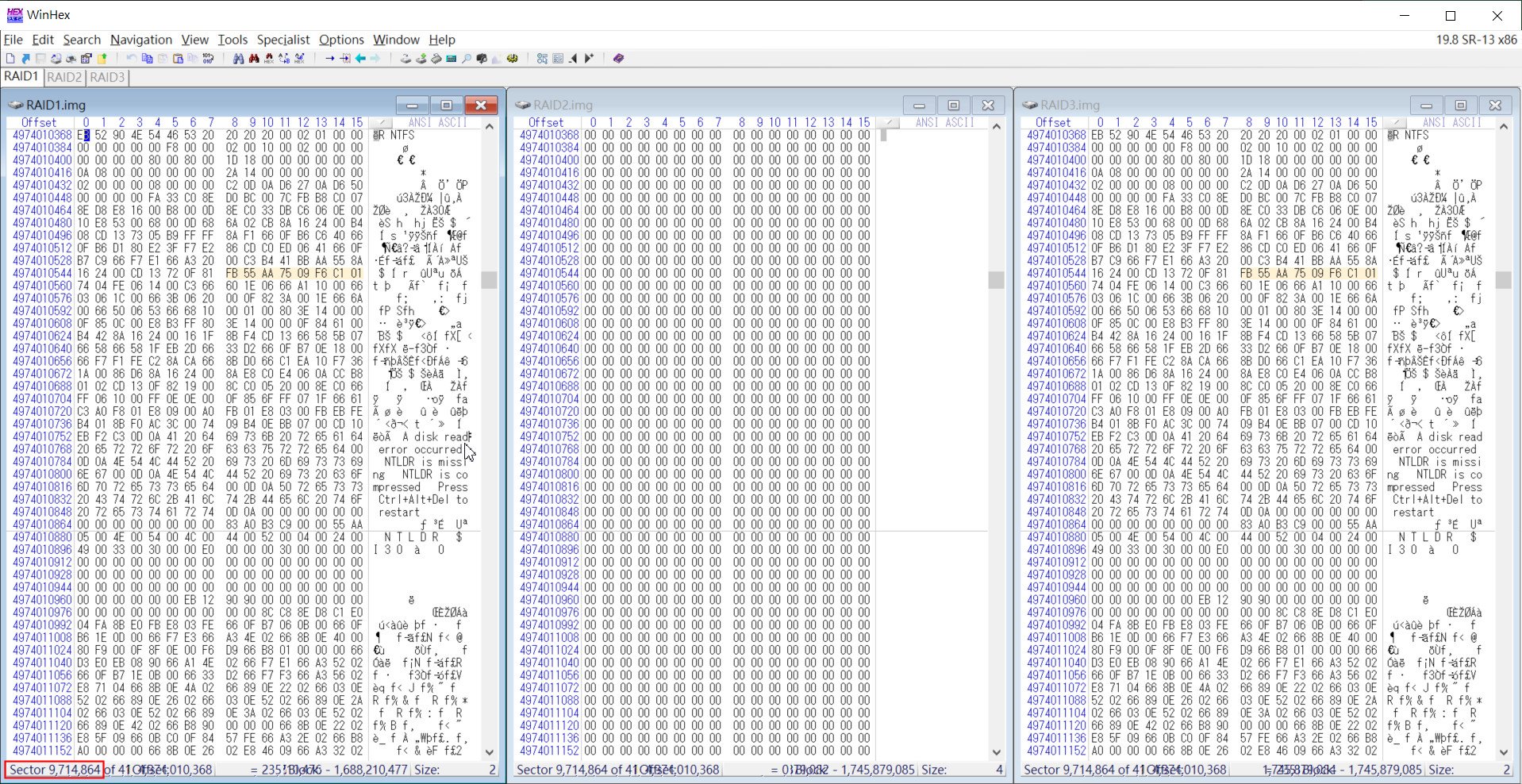
▲另搜尋RAID1.img或RAID3.img的NTFS Boot Loader時,在9,714,864 磁區找到。這個就太後面了,且暫時無法得知哪組是真資料碟,哪組是核對碟
上述的結果,發現RAID3.img硬碟在Sector (磁區) 264,192能最優先找到。至於其他RAID1.img或RAID2.img的磁區都太後面或找不到,因此可以先假定RAID3.img是RAID5陣列中的第一顆Stripe碟。
-
搜尋 MFT Record所在的位置
接下來要找出MFT (Master File Table,主檔案查詢表) Record的位置。這時要針對不同RAID碟來進行搜尋,且要多次搜尋,以找出MFT Record所對應的Cluster號碼。我們先找出MFT的特徵字串: FILE0,同樣也是在Offset為0處。如下圖:
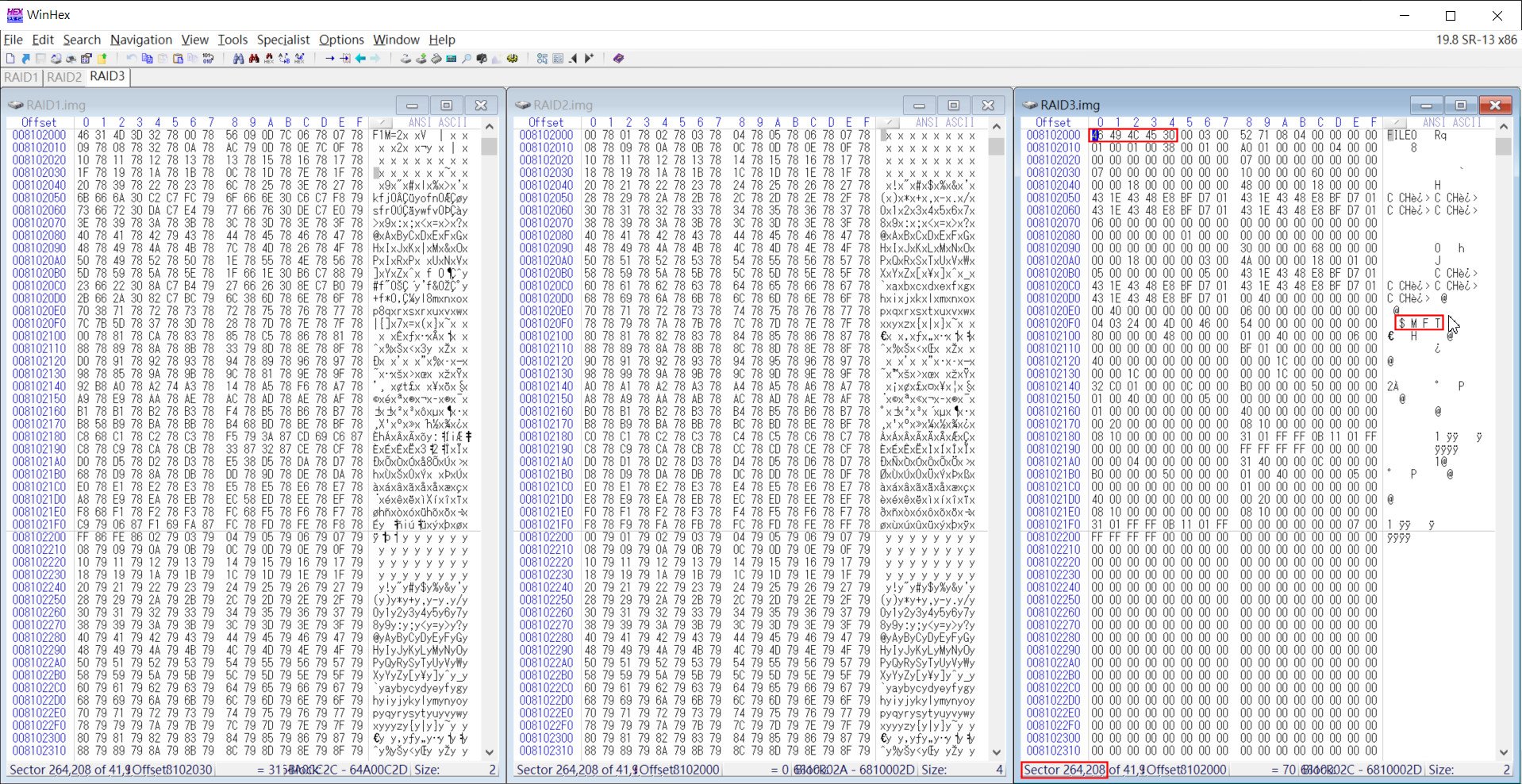
▲搜尋MFT Record的特徵碼,並確定有找到$MFT檔案名稱,於RAID3.img碟找到
上述的搜尋結果,在RAID3.img碟的Sector 264,208有找到。也有發現 $MFT的字串,因此該Sector的資料也符合我們期望的結果。
-
搜尋File Record特徵,嘗試找出最近的兩個磁區
接下來,我們要針對每顆RAID碟進行尋找File Record的動作,這部份的動作會比較繁瑣,且建議用Excel或是其他軟體將搜尋結果一一記錄下來,以利接下來的RAID重組需求。同樣這部份同樣也是要先搜尋FILE0特徵碼,並檢視其檔案名稱,以先得知各RAID碟的檔案現存狀態。
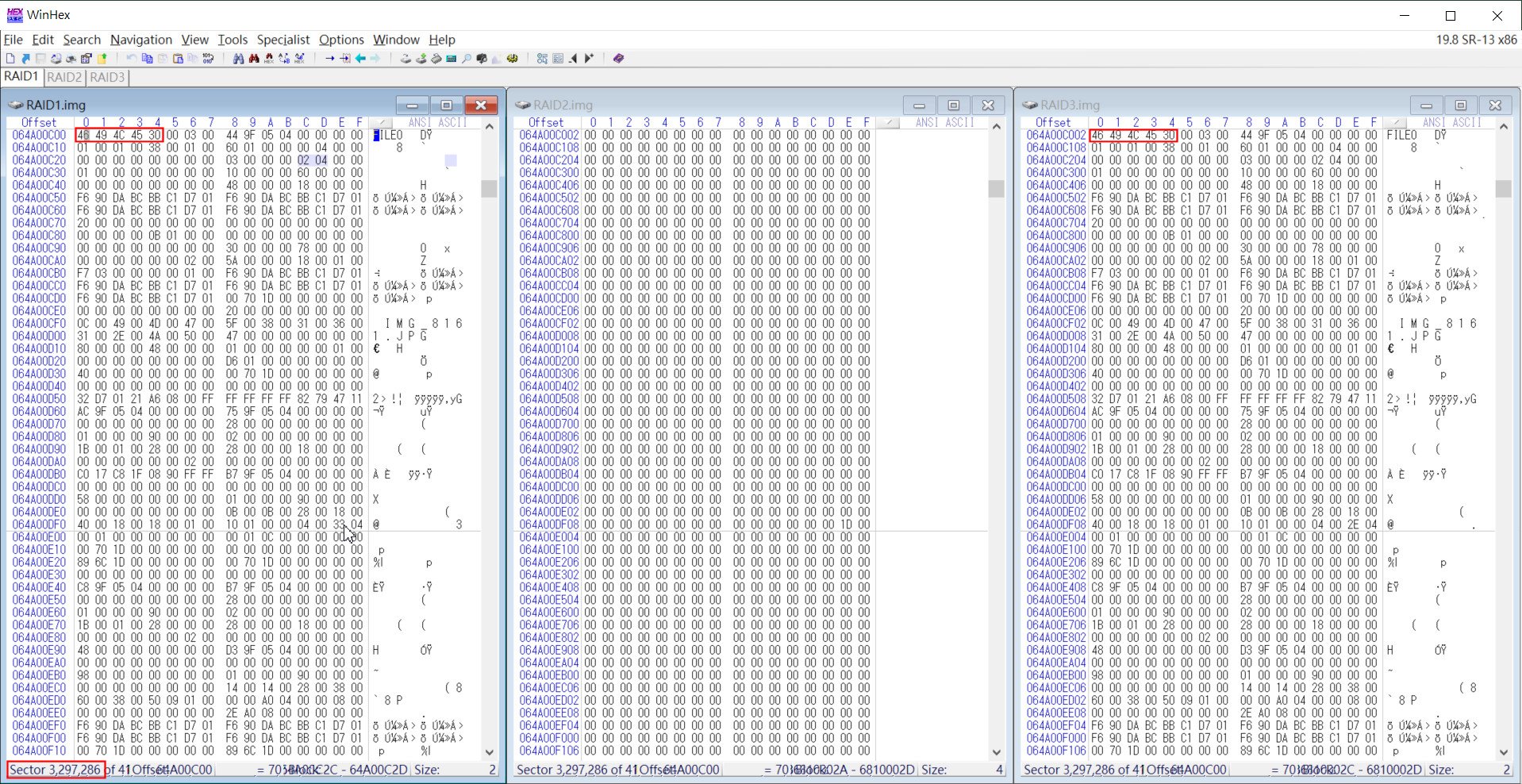
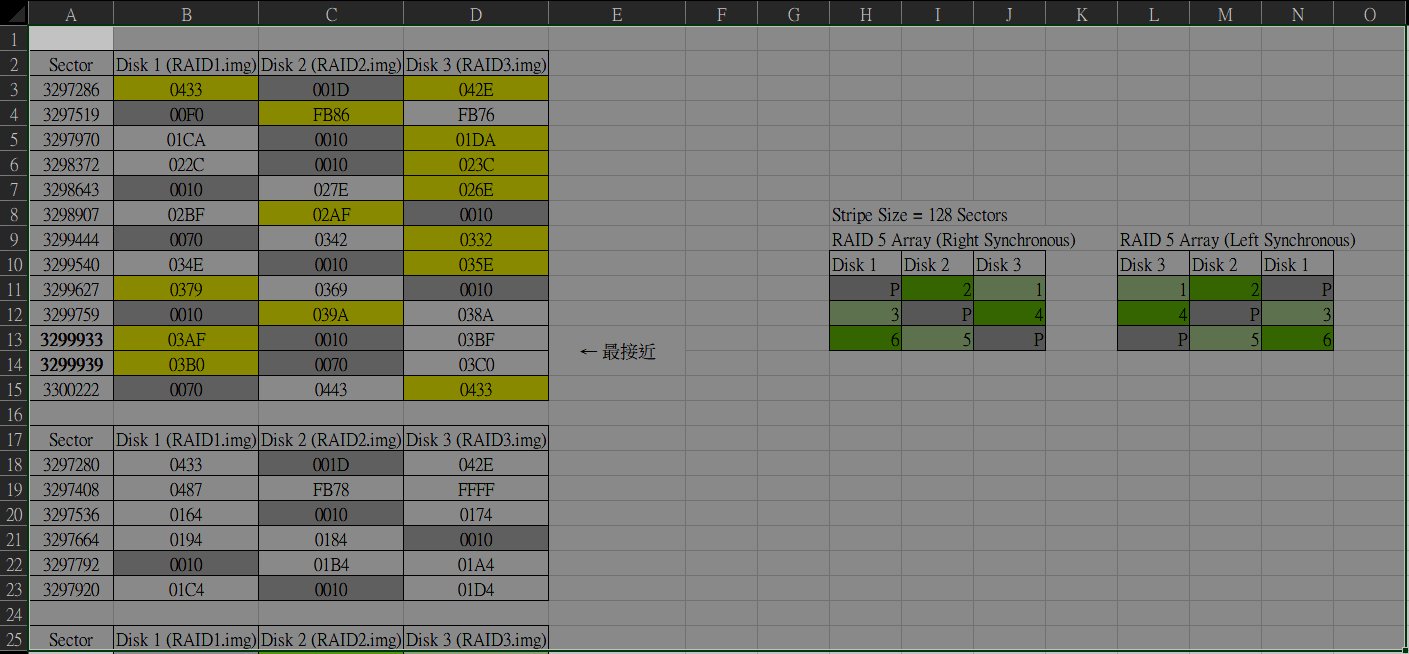
▲ 搜尋File Record的特徵碼,在RAID 1和RAID 3的Sector 3,297,286都有找到,可得知其中一個碟可能是資料碟,而另一組應該是核對碟
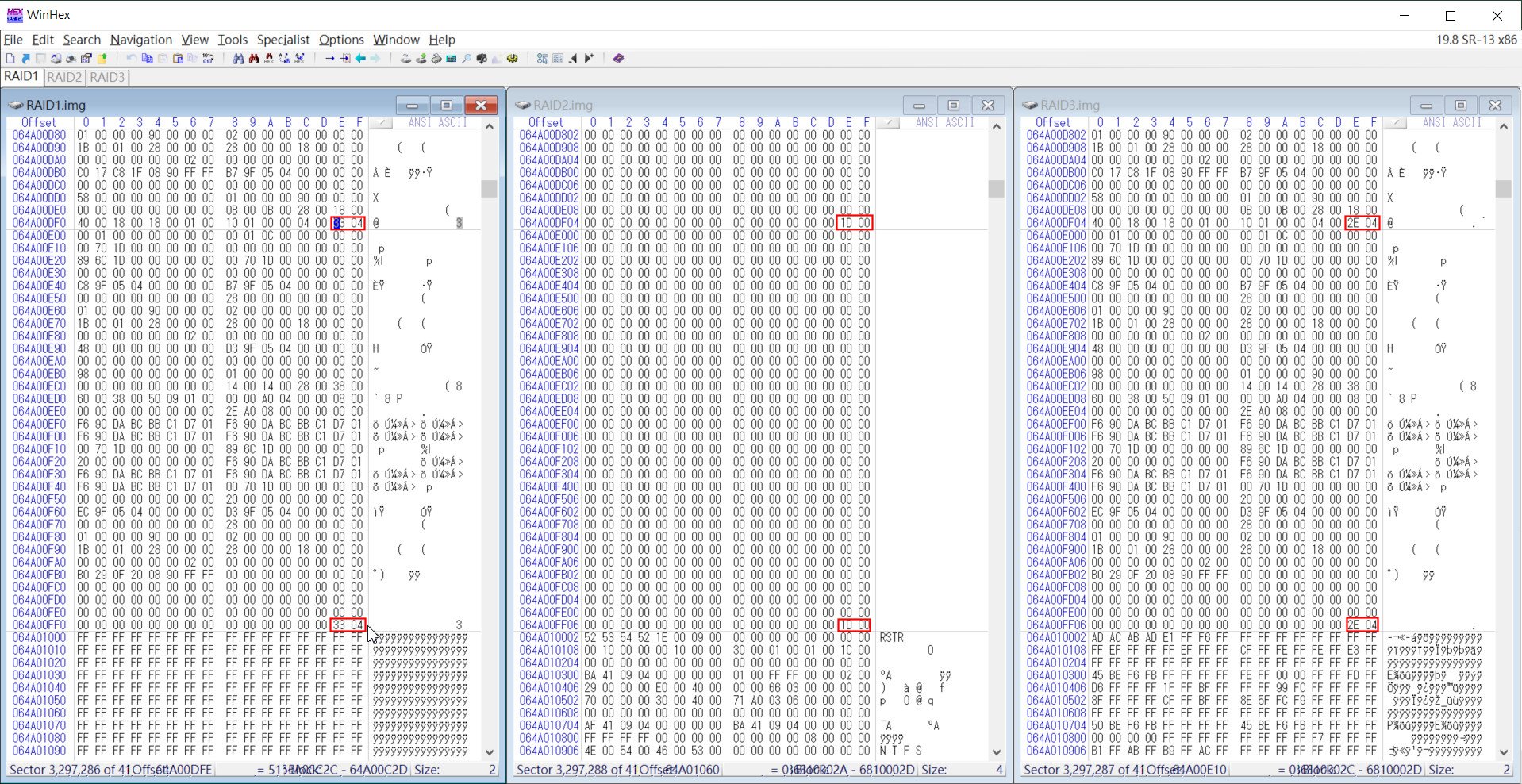
▲ 往下方檢視該Sector的Offset 01FE處,會有一組Cluster Code (磁簇碼),在RAID 1碟為0433,RAID 2碟為001D,RAID 3碟為042E,這些值都記下來
先在RAID1 碟找出幾個FILE0特徵碼,並記錄其所在的Sector (磁區)、位於01FEh處的磁簇碼,同時將其他兩顆RAID碟 (RAID 2 & 3)的01FE碼都記下來。這個步驟大概先找個4~5個這樣的磁區,並將磁區號碼,磁簇碼都記下來。
接著也針對RAID2.img和RAID3.img進行跟RAID1.img同樣的搜尋動作,找出4~5個帶有FILE0特徵碼的磁區號碼和磁簇碼,一一記錄下來。
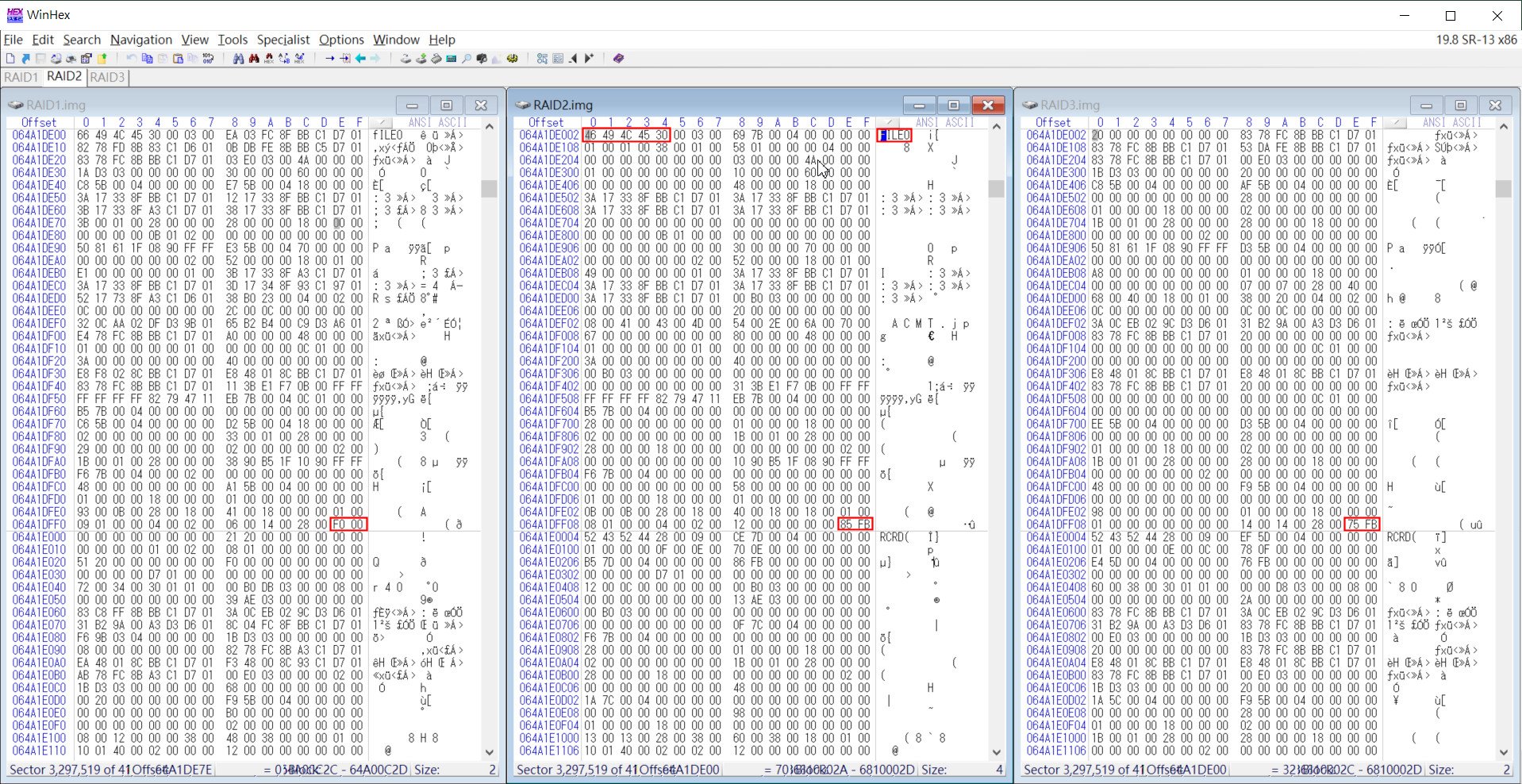
▲ 同樣在RAID2.img搜尋FILE0特徵碼,並記錄該Sector的Offset 01FE 磁簇碼,以及同磁區對應的RAID1.img和RAID3.img的磁簇碼
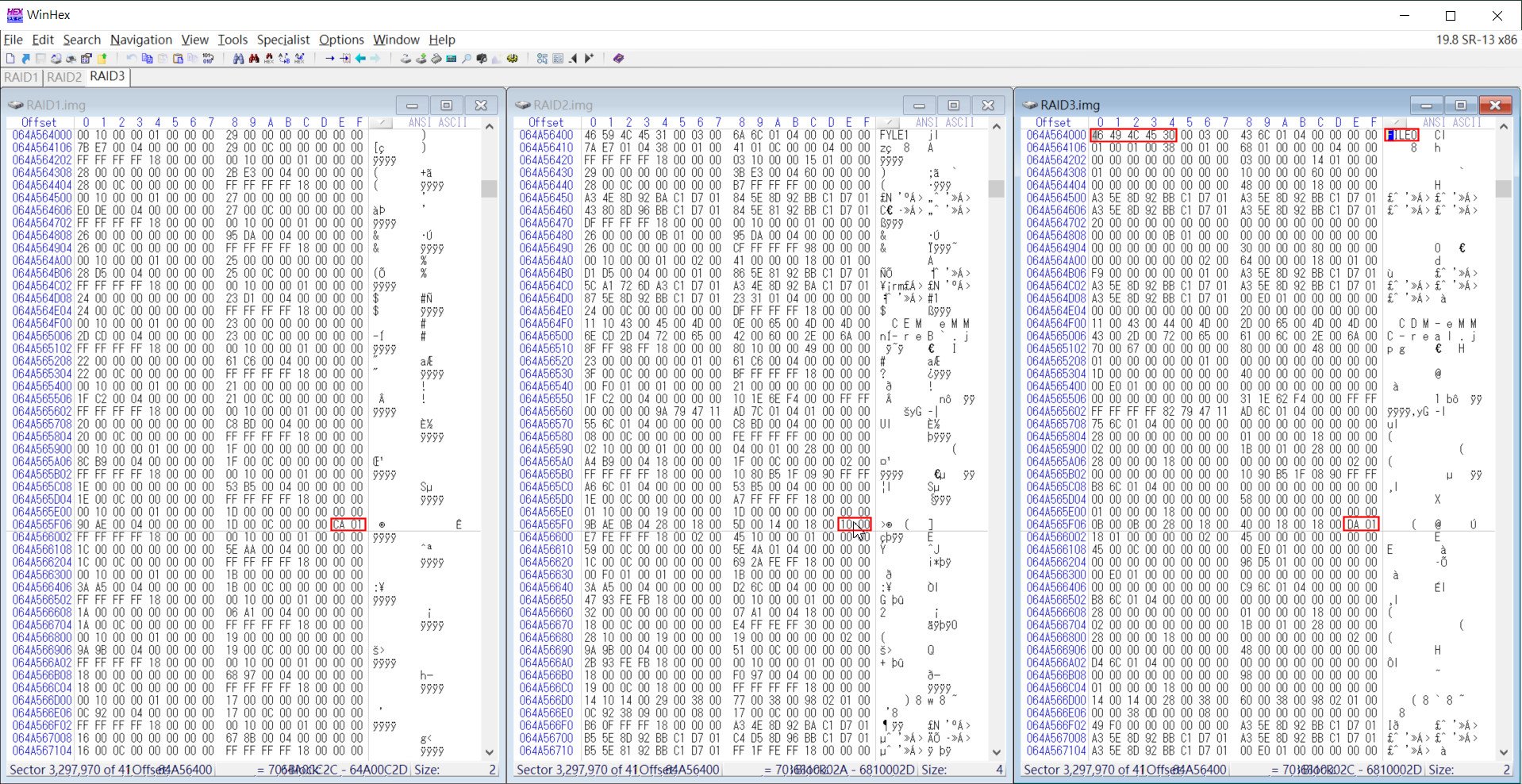
▲ 在RAID3.img搜尋FILE0特徵碼,並記錄該Sector的Offset 01FE 磁簇碼,以及同磁區對應的RAID1.img和RAID2.img的磁簇碼
上述的動作,大概每個磁碟都找了含有FILE0特徵碼大約4~5個磁區後,就可以整理出如下的這種表格。
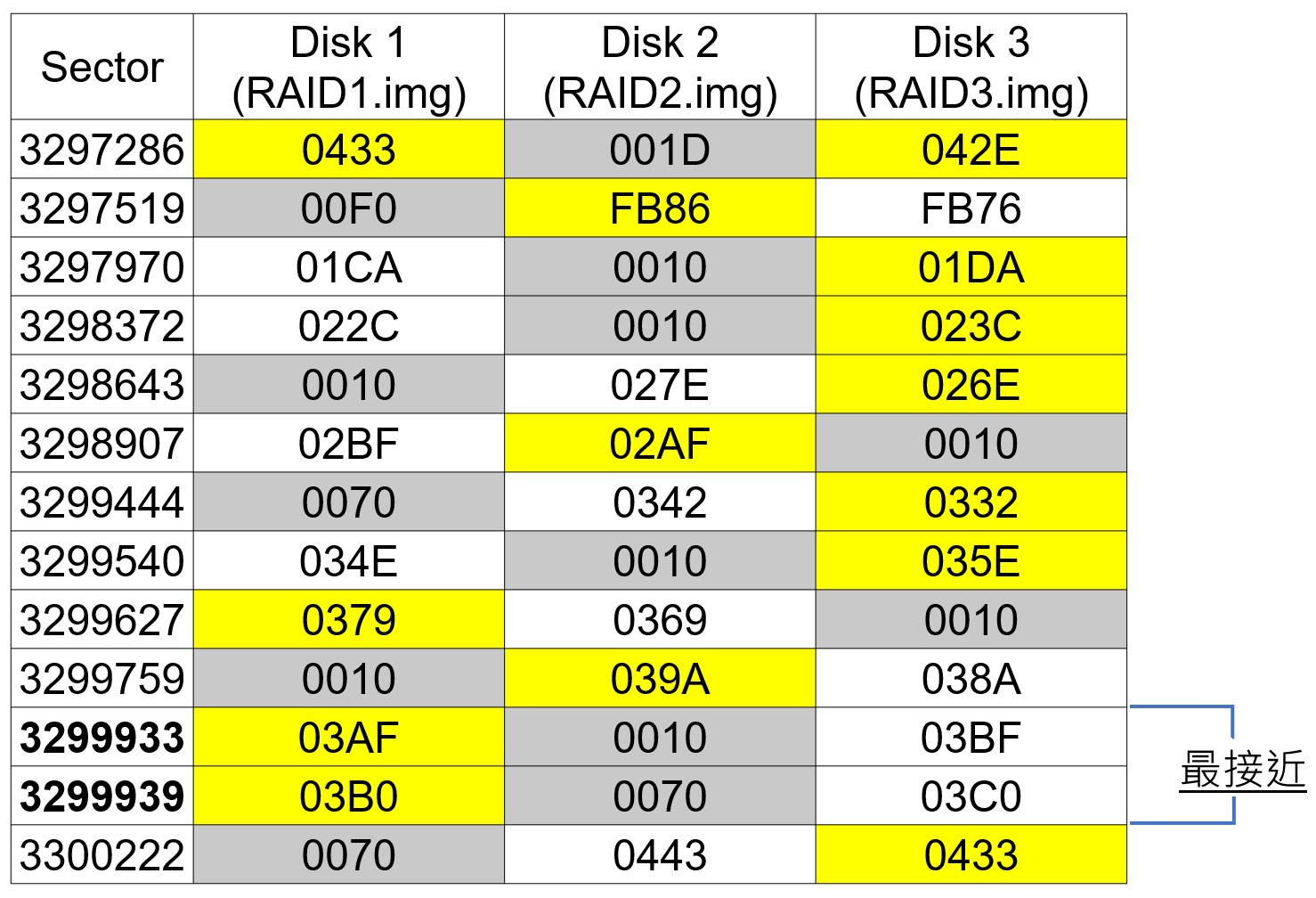
上述黃底表示為有找到FILE0特徵碼的RAID1碟與其磁簇碼(Cluster Code),而灰色表示其磁簇碼應該是核對碟。而核對碟的值都是其他兩碟進行 eXclusive OR (XOR) 運算後的值(例如03AF xor 03BF = 0010)。而從上述所找到的磁區表中,可以發現擁有FILE0特徵碼的兩個最近的磁區,為3299933和3299939,因此我們可以接下來可以再從這些磁區裡面,慢慢找出磁簇碼的連續關係。
-
確認Cluster對應的磁區數與Stripe長度
接下來,我們就先以上述最接近的兩個磁區中,以RAID 1碟開始,找出磁簇碼從 03AF變動到03B0的第一個磁區。我們就先從Sector 3299939開始往上找,請參考下圖。
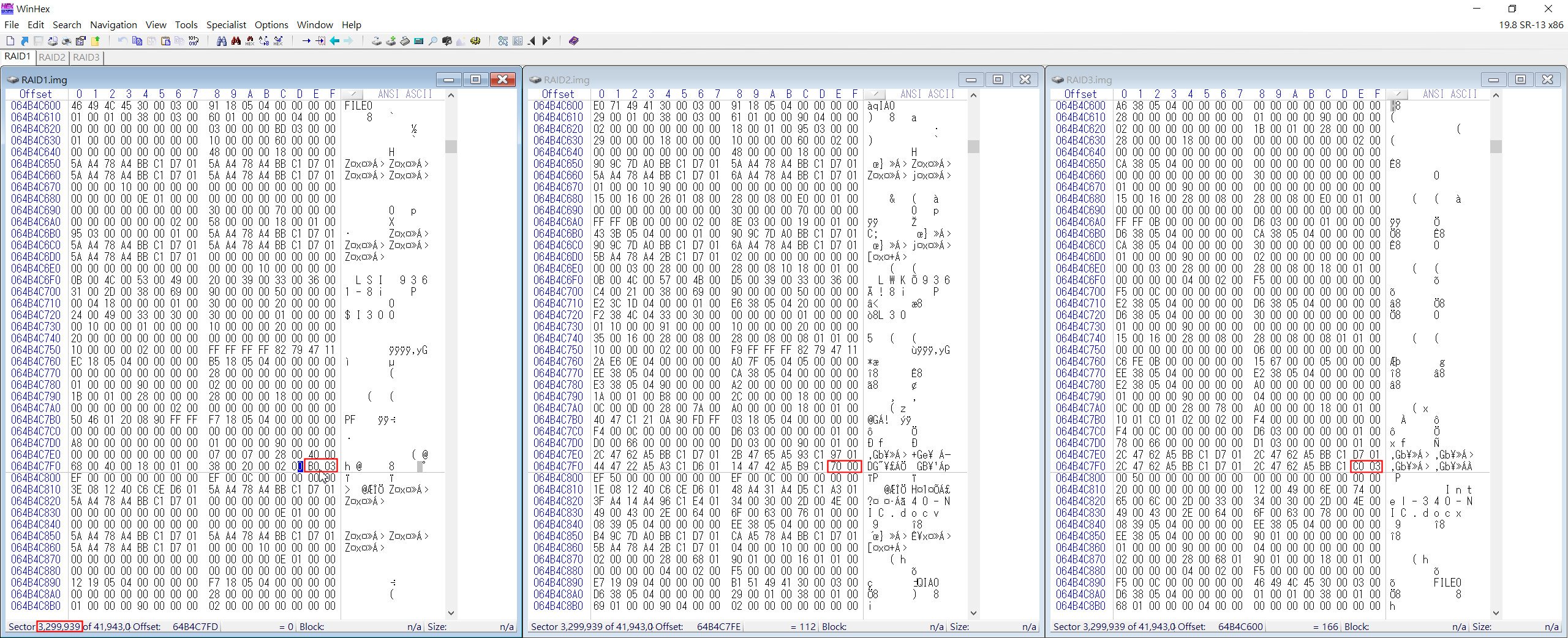
▲ 從Sector 3299939的RAID 1碟中找到其磁簇碼為 03B0
這次將磁區往前翻到3299936時,其磁簇碼為03B0,而磁區3299935就變成03AF,由此可知3299936就是含有磁簇碼為03B0的第一個磁區。
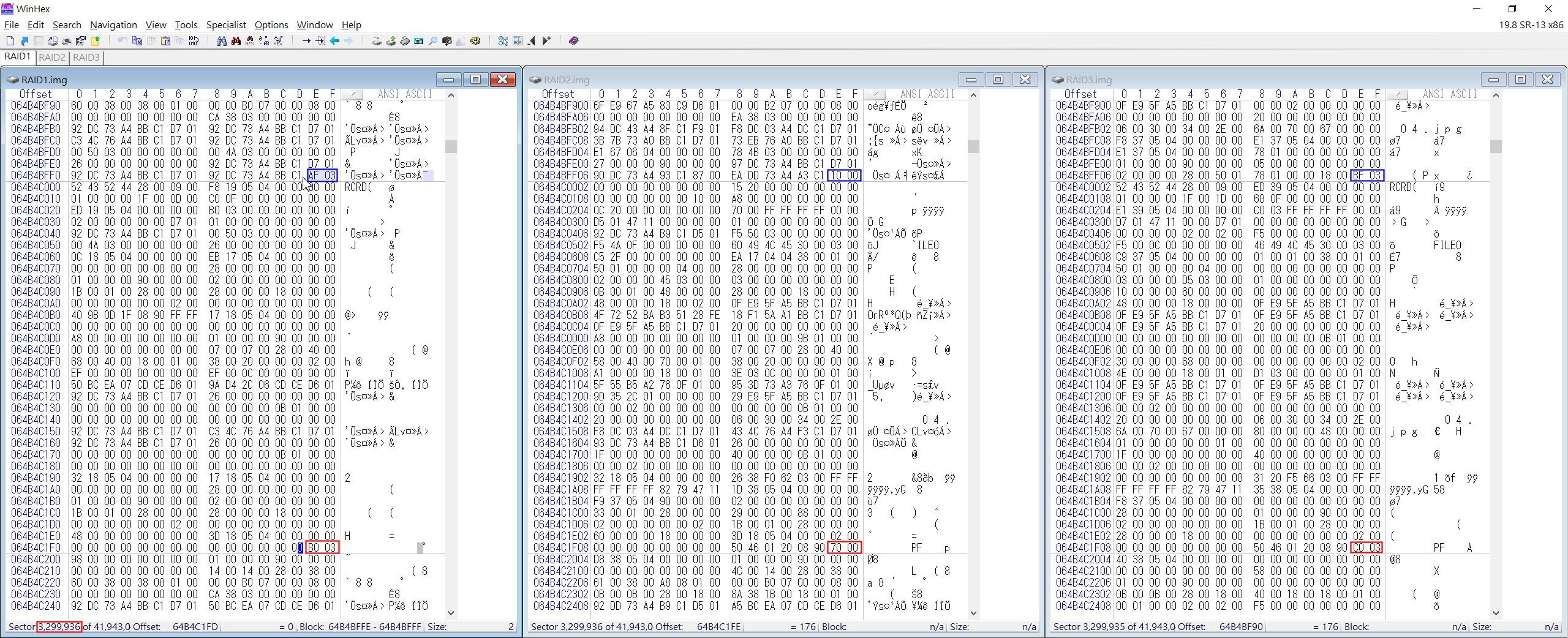
▲ 往上翻Sector至 3299936時,其上一個Sector的磁簇碼已變成 03AF (藍框)
接下來就來算出 03B0總共佔了幾個磁區,此時再將磁區往下翻,翻到可以看到03B1的第一個磁區,就可以算出這個RAID陣列的磁簇長度了。
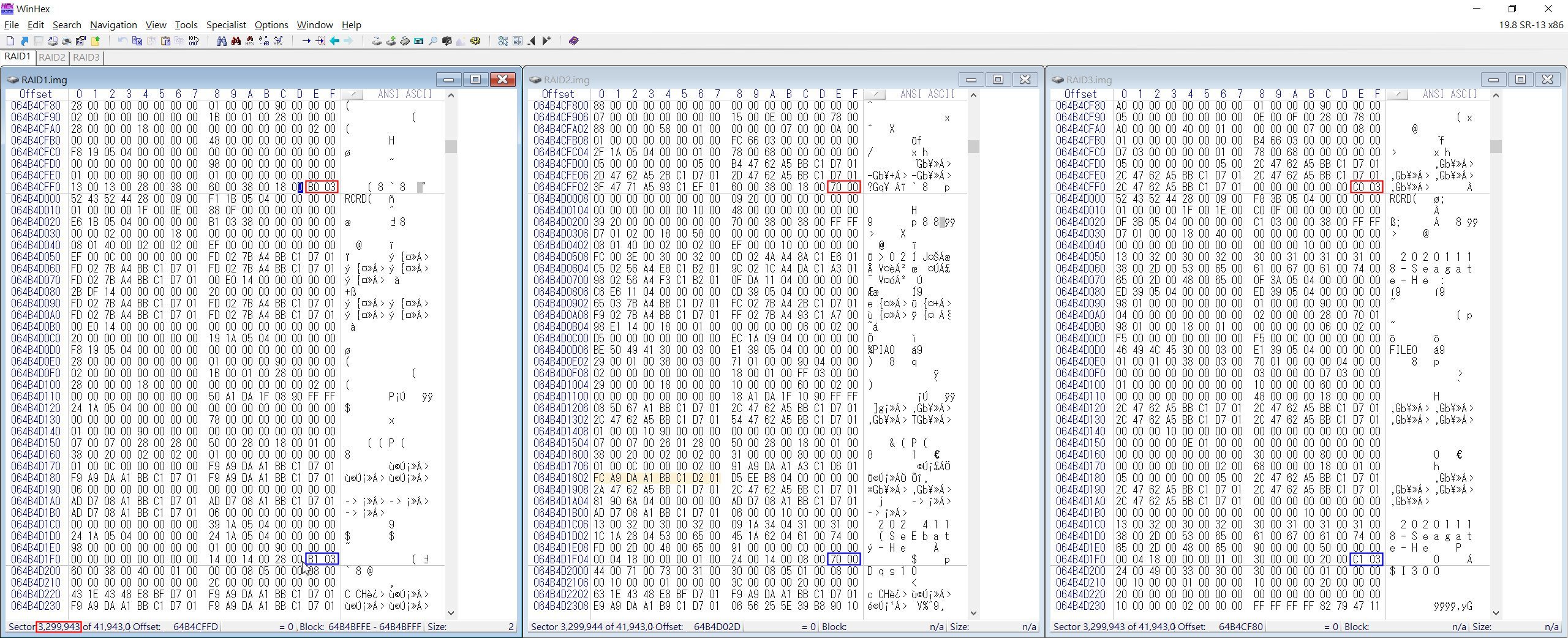
▲ 再往下翻Sector至 3299943時,其下一個Sector的磁簇碼已變成 03B1 (藍框)
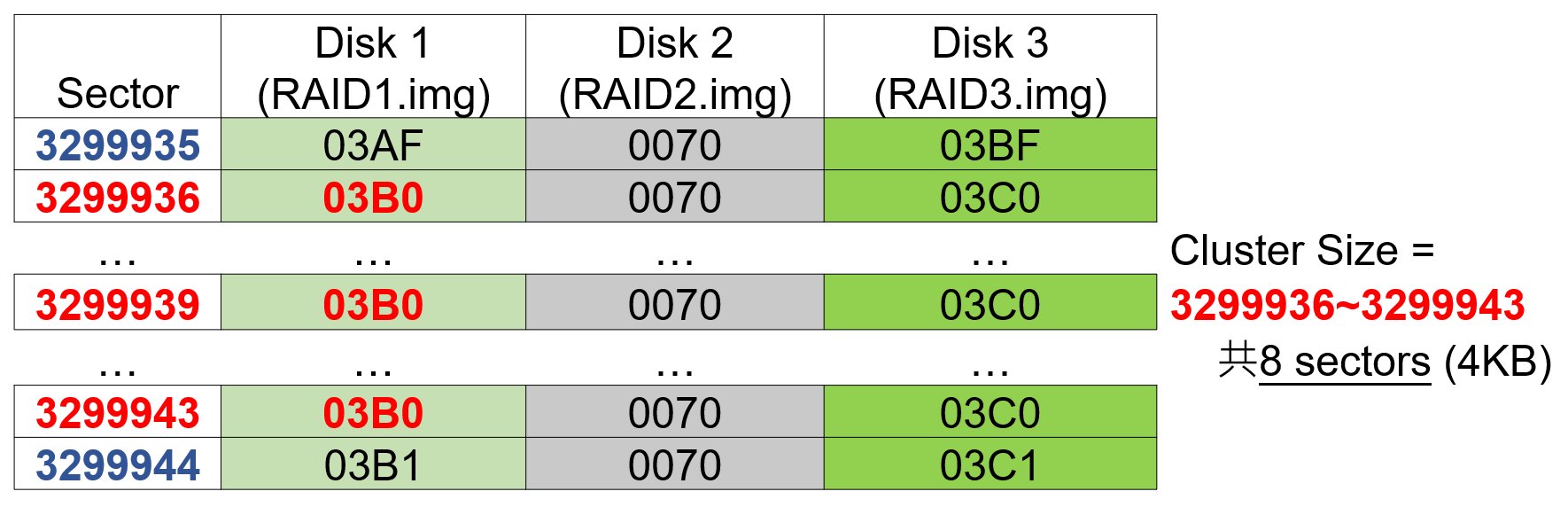
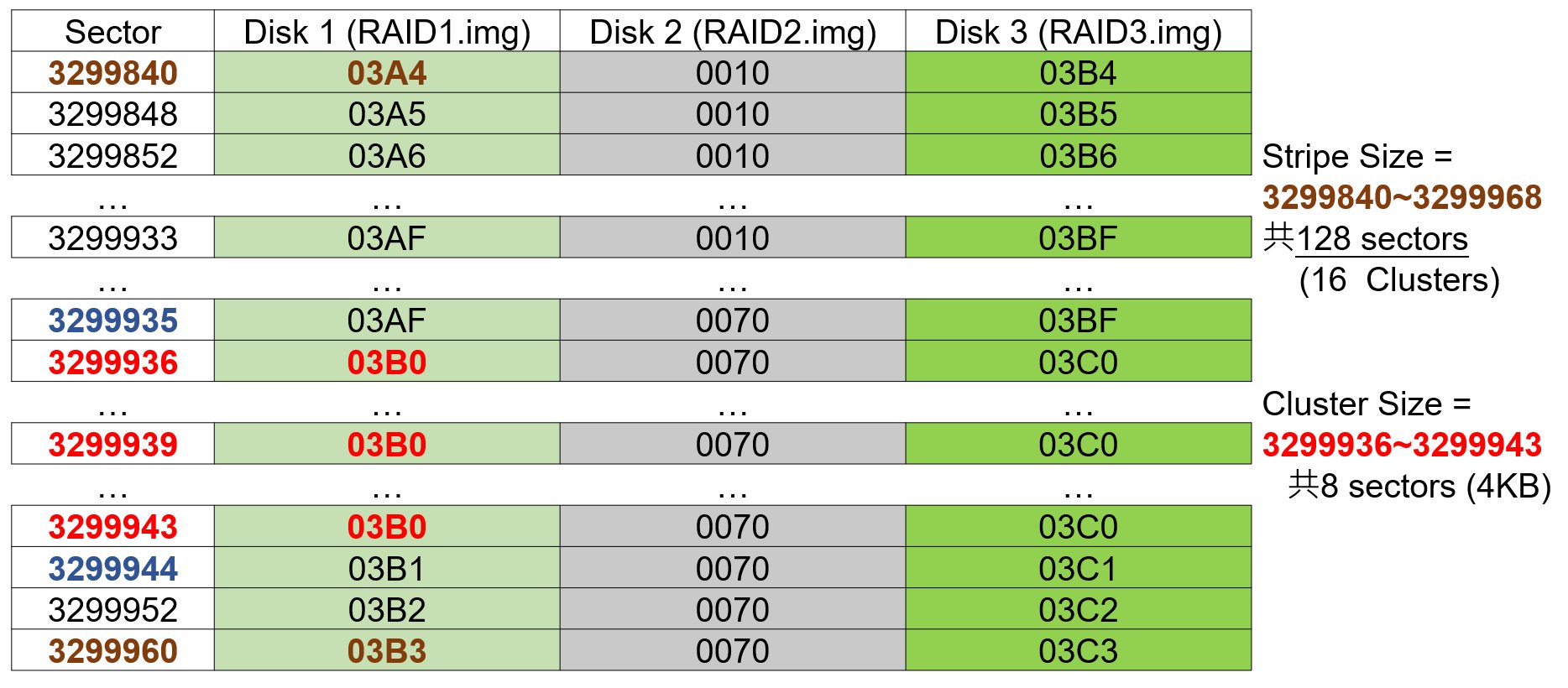
因此可以算出Cluster Code 03B0 所佔用的磁區是 3299936~3299943,也就是8個磁區,而一個磁區為512 Bytes (0.5KB),因此可以算出這個RAID的Cluster Size為 0.5KB * 8 = 4KB。整理表格如下:
-
確認Stripe對應的磁區數
知道Cluster Size之後,接下來就要查出 Stripe Size (條帶碼長度)。這次我們一樣以查出Cluster Size的方式,擴大磁區範圍來算出Stripe Size。我們先向上翻磁區找到Cluster Code變動到其他RAID碟的地方,然後再往下找一次。
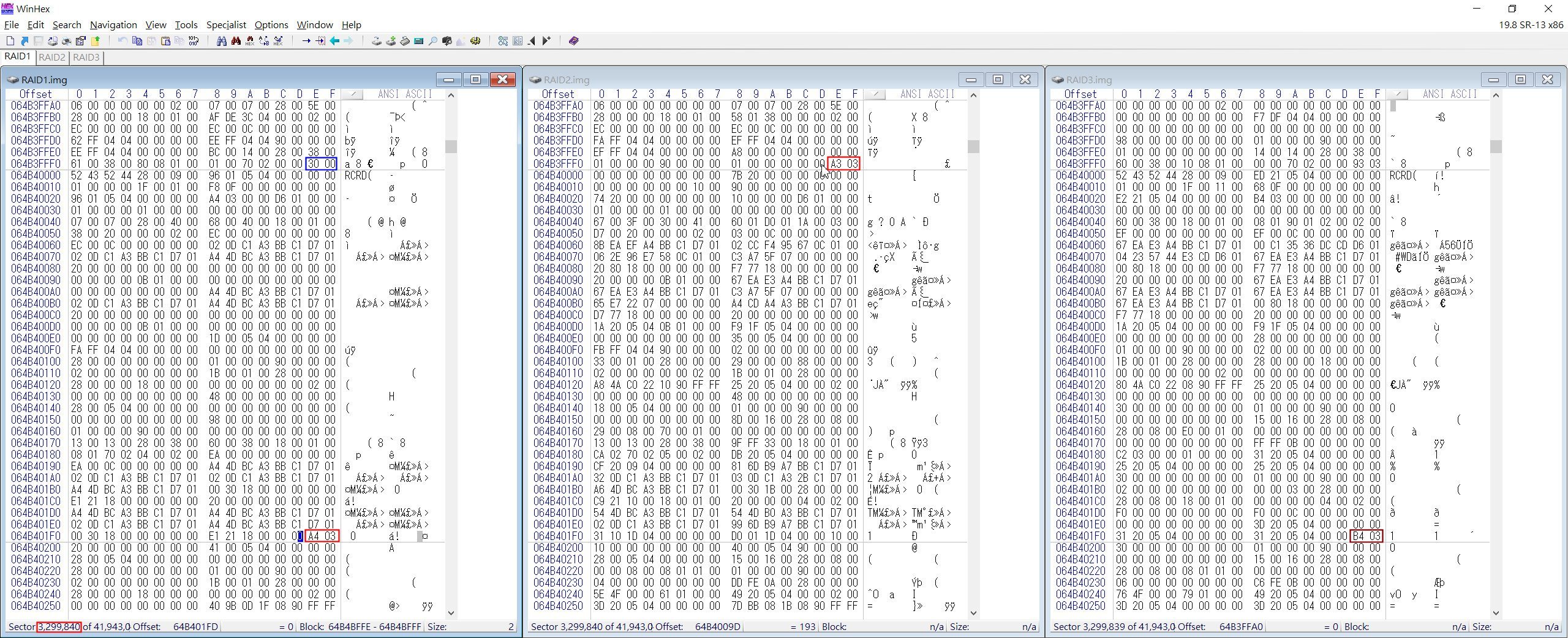
▲ 往上翻Sector,翻至 3299840時,磁簇碼為 03A4,再往上一個Sector的磁簇碼已變到 RAID2.img 的 03A3 (紅框),而原RAID1.img的地方變成核對碼(藍框)。請注意RAID3.img的磁簇碼為 03B4 (棕框)
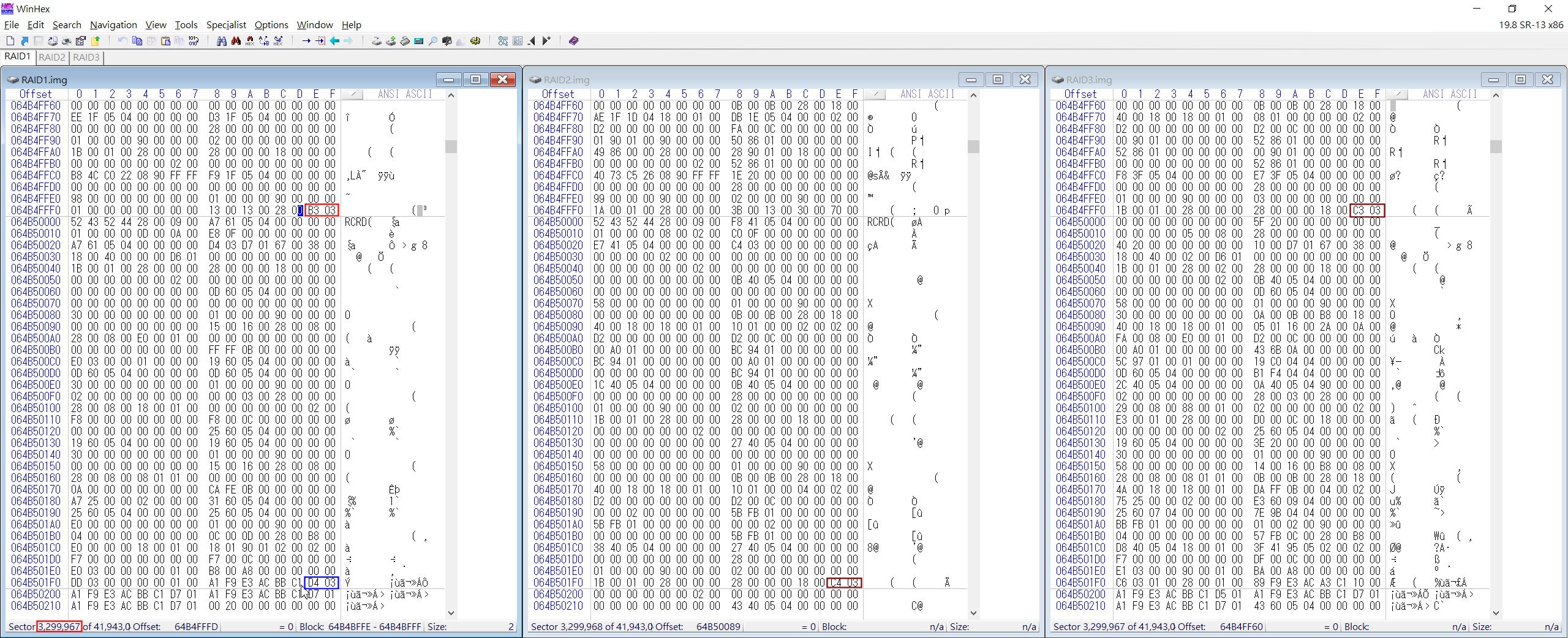
▲ 往下翻Sector,翻至 3299967時,磁簇碼為 03B3,再往下一個Sector的磁簇碼已跳到 03D4 (藍框)。可留意上一張圖的03B4是從RAID3.img開始的,直到這張圖的03C3 (棕框),再下一個Sector 的03C4則從RAID2.img開始。
從前面得知Cluster Size為4KB,至於Stripe Size則是找出單一RAID碟的連續Cluster碼,直到變動到其他RAID碟為止。尋找的方式如上兩圖。
而從上面的圖可發現,從Sector 3299840~3299968有連續性Cluster數字,因此可以得知這個RAID陣列碟的Stripe Size為 128 Sectors,也就是64KB。表格整理如下:
-
建立RAID Stripe排列順序
從上面可得知Stripe Size為128 Sectors,也就是64KB。因此每個條帶只要經過128 Sectors就會變動位址。上述可以得知:
- Sector 3299832時,RAID 2和RAID 3的Cluster Code為03A3、0393。
- Sector 3299840至3299960時,RAID 1和RAID 3的值為03A4~03B3、03B4~03C3。
- 最後在Sector 3299968時,條帶變動到RAID 1和RAID 2,Cluster Code分別為03D4、03C4。
上述可以大致看出其規律性,接著我們可以再將條帶對應的磁區範圍再拉大,並歸納出表格如下:
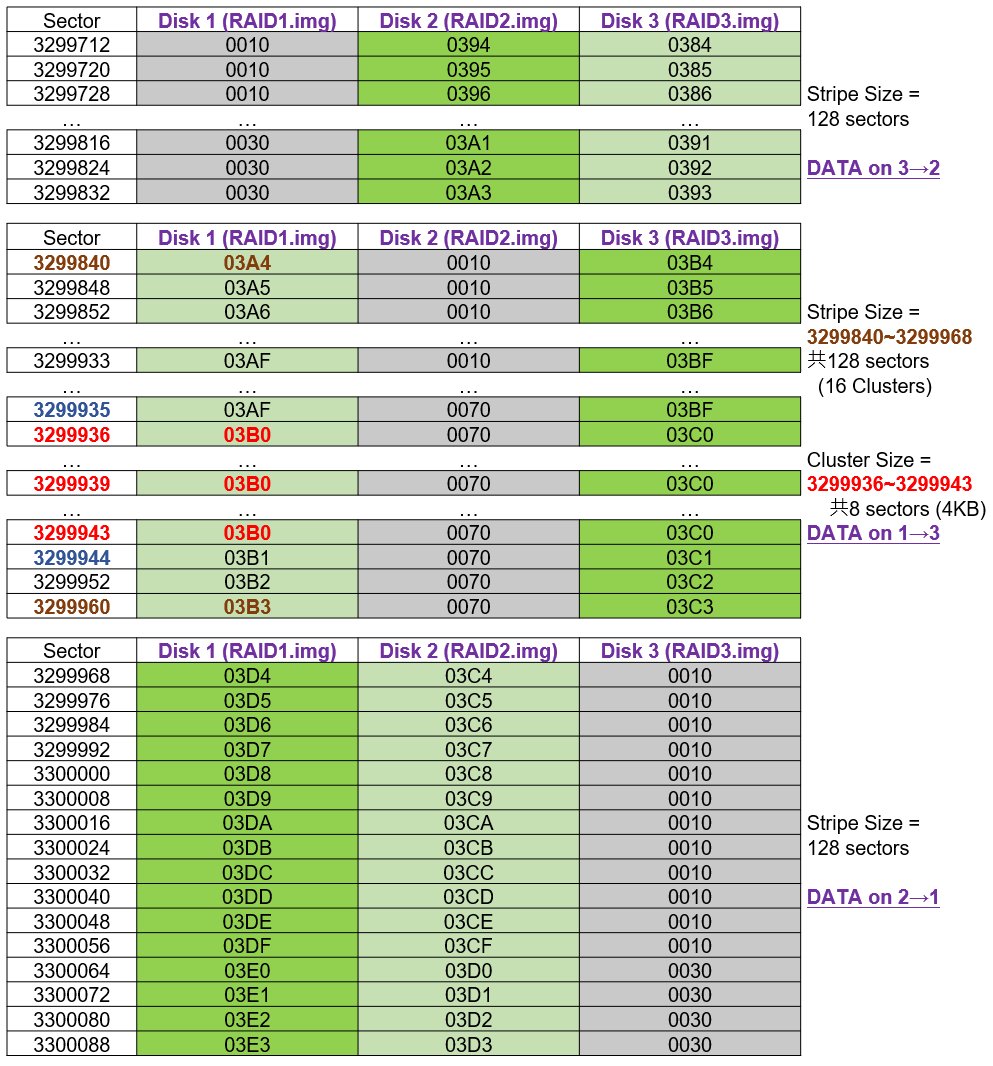
上表可以看到第一組Stripe區,是分佈在RAID 3和RAID 2,Cluster碼為0384~0393,接著是0394~03A3。然後第二組Stripe區,分佈在RAID 1和RAID 3,Cluster碼為03A4~03B3接著是03B4~03C3。最後第三組的Stripe區分別分佈在RAID 2和RAID 1,Cluster碼為03C4~03D3接著是03D4~03E3…
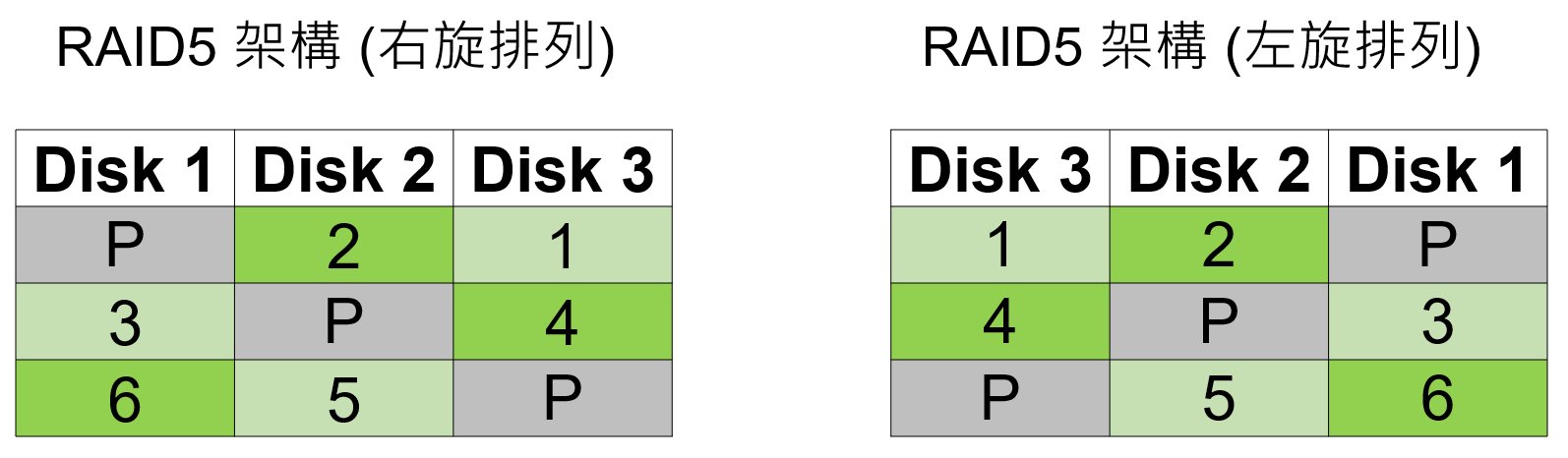
因此可以得知,第一區的順序為 RAID 3→2,第二區順序為RAID 1→3,第三區順序為RAID 2→1,接著就可以排出RAID的順序如下:
-
於救援軟體重建RAID架構,以將資料導出
從上分析終於得知RAID 5的Cluster Size、Stripe Size (或Block Size),以及RAID Sequence之後,就可以執行支援RAID的救援軟體(如R-Studio),來將陣列組合還原,以便進行資料救援。
以下就是實際將上述的RAID陣列,透過R-Studio軟體來進行重組與救援。
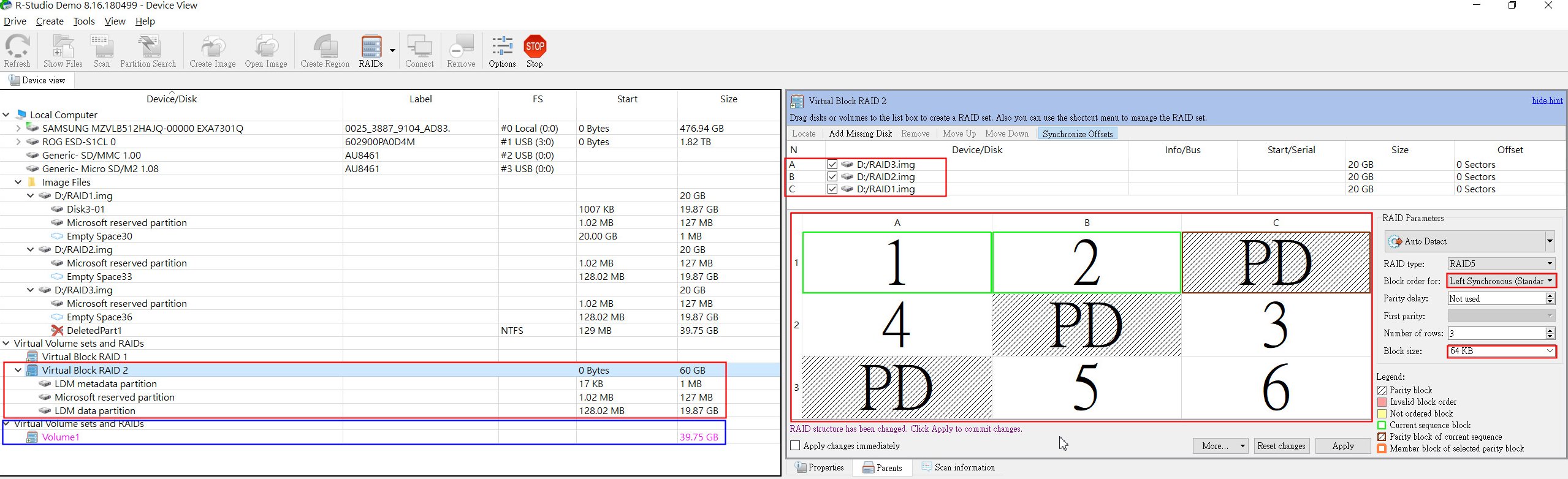
▲ 將三顆RAID磁碟陣列的映像檔載入,並建立Virtual RAID 5,把RAID Structure照前述的方式建立起來,以左旋(Left Synchronous)為例,A/B/C列分別對應到RAID 3/2/1,並確認Stripe Size (Block Size)為64KB。
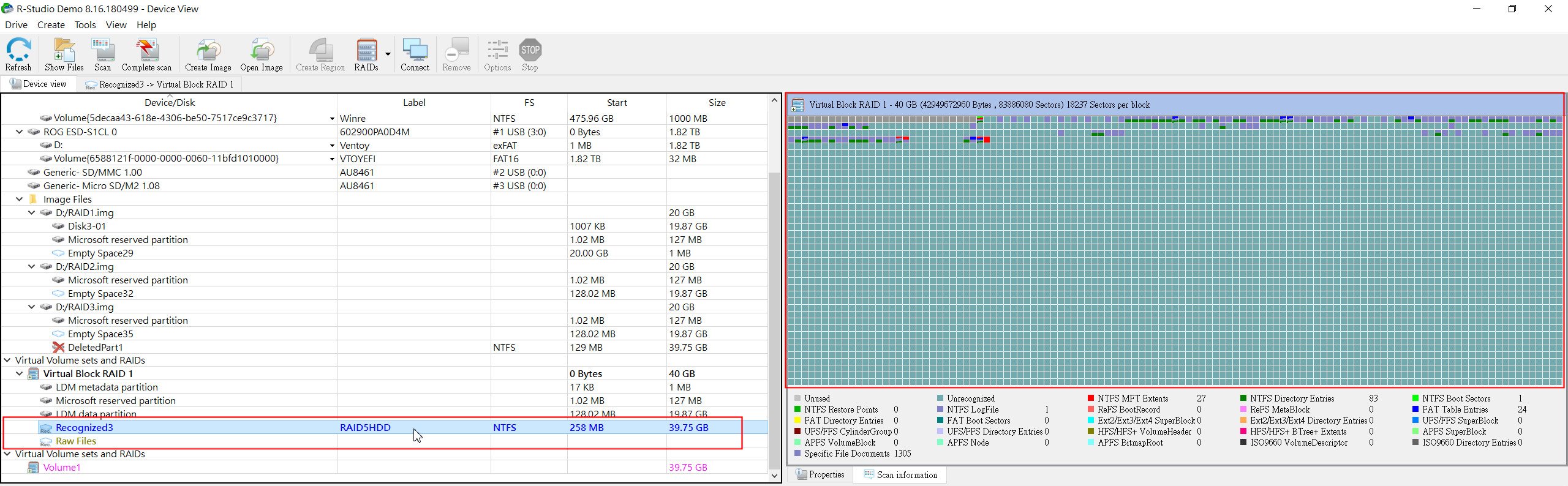
▲ 若參數都輸入正確,就可以開始進行掃描,畫面左邊的Virtual Block會顯示Recognized,表示軟體有正確抓到該RAID架構。
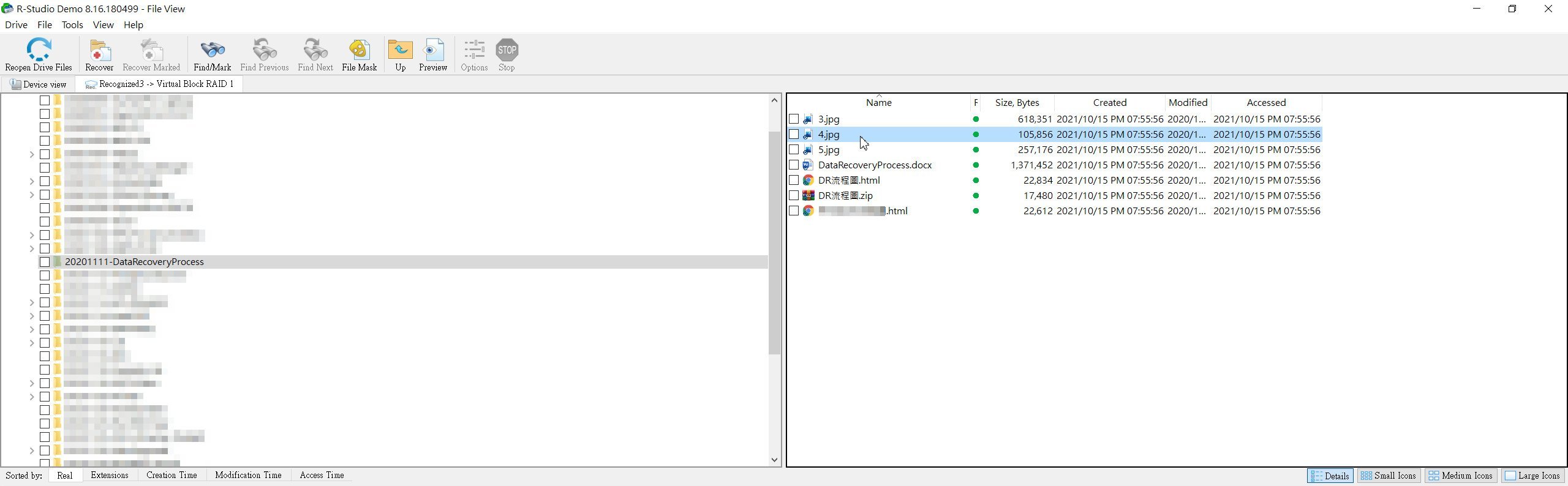
▲ 掃描一陣子之後,R-Studio會列出找到的目錄與檔案,並一一列出來。
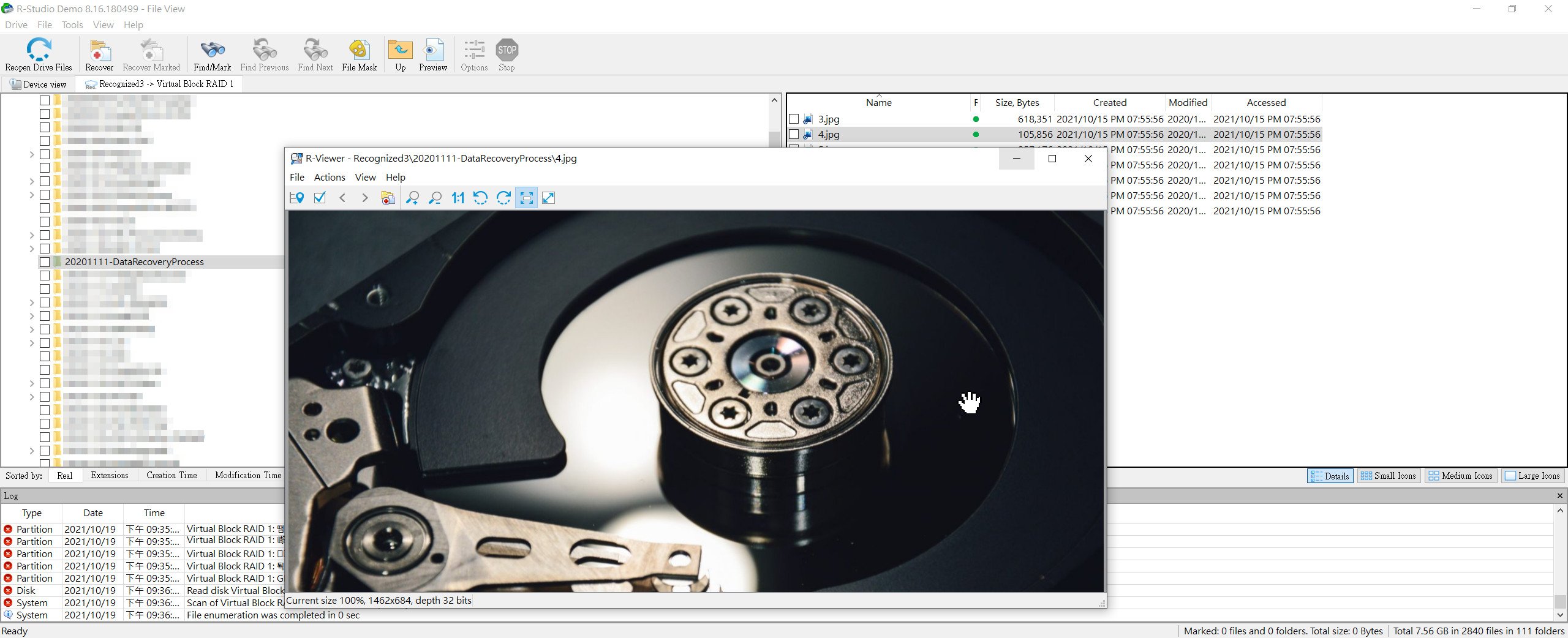
▲ 以圖檔為例,點擊之後,若無問題,應該可以正確秀出照片內容。資料救援成功!
結語
從上面的實作過程,可以了解RAID 5磁碟陣列的重組方法,先分析檔案系統,再從特定的特徵碼(Signature),找出對應的磁區(Sector)編號,再分析出磁簇(Cluster)大小,逐漸擴大磁區搜尋範圍,找出條帶(Stripe)或區塊(Block)大小,進而分析出RAID的排列(Sequence)方式,最後再請出資料救援工具來掃描RAID VD,以便將資料搶救回來。
總之,RAID磁碟的前期分析、計算、排列與重組,是資料救援之前最重要的步驟,一旦建構錯誤,就無法將資料正確救援出來。只要能先將前面的動作都確實做好,那麼後續的資料救援工作就會稍微輕鬆一些。希望本文的實作能對大家有所幫助!
